Raspberry Pi や NUCBOX などのサーバーで複数の監視スクリプトを動かして InfluxDB にデータを蓄積しても、「どのデータがどこにあるか」を個別に確認するのは大変です。
本記事では、InfluxDB v2 に記録したサーバーの各種情報(CPU・SSD温度・プロセス状況・バックアップ状態など)を Grafana の1つのダッシュボードに集約して一元管理する方法を解説します。
なぜこの機能を作ったのか?
サーバーの監視スクリプトを増やすにつれて、InfluxDB 上のデータも増えていきました。「CPU 温度が高くなっていないか」「バックアップは正常に終わっているか」「特定のプロセスがエラーになっていないか」といった確認を毎回コマンドで行うのは非効率です。
Grafana でダッシュボードを一枚作れば、ブラウザを開くだけでサーバー全体の状況が一目でわかる状態にできます。異常値は色変化で即座に気づけるよう設定しています。
サーバーの状態をブラウザで開いた瞬間に全部わかるようにしたい!
実現したいこと
- CPU温度・使用率・周波数・メモリ使用量をリアルタイムに表示する
- SSD温度・消耗度・累積読み書き量を表示する
- 稼働中のプロセスのCPU・メモリ使用状況を一覧で表示する
- 自作アプリの実行ログを表示して、正常動作しているかを確認できる
- バックアップの最終実行時刻・フォルダ容量・ファイル数を表示する
- 各種APIの実行回数など、スマートホームの活動量を可視化する
この記事でわかること
- Grafana に InfluxDB v2 データソースを接続する方法
- Stat・Gauge・Table・Time series などの各パネルの使い分け方
- InfluxDB v2 のデータを Flux クエリで取得する基本的な書き方
- 閾値(Thresholds)設定で異常値を色で警告表示する方法
- 複数の monitoring measurement をまとめて1つのダッシュボードに配置する方法
必要な準備と用意するもの
- Linux 搭載サーバー(Raspberry Pi / NucBoxなどのミニPC 等)
- InfluxDB v2(稼働済み・データ収集済み)
- Grafana(稼働済み)
- 各種監視スクリプト(データ収集済み)
- nucbox_system_record.py(CPU・メモリ・NVMe)
- process_status_record.py(プロセス状況)
- raspi_backup.py(バックアップ情報)
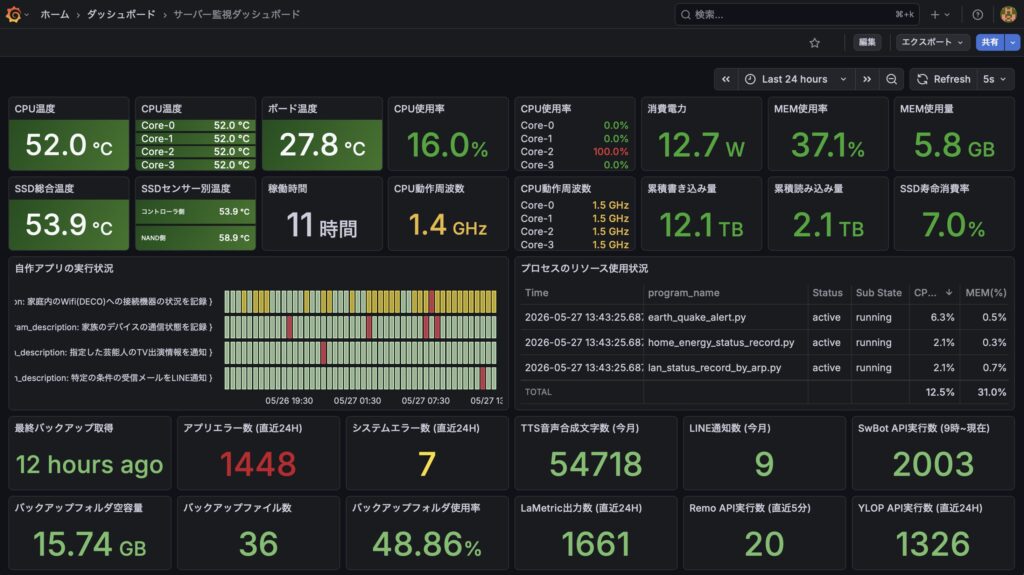
完成イメージ
完成したダッシュボードは以下のような構成になっています。
ダッシュボードは大きく4つのエリアに分かれています。
- エリア①(上段):CPU温度・コア別温度・CPU使用率・消費電力・メモリ使用率/使用量
- エリア②(中段):SSD温度・稼働時間・CPU周波数・累積読み書き量・SSD消耗度
- エリア③(下段左):自作アプリの実行状況ログ・プロセス別リソース使用状況テーブル
- エリア④(下段右):バックアップ状況・エラー数・各種APIの利用数統計
システムの仕組み
データの流れ
各監視スクリプトが定期的にデータを InfluxDB v2 に書き込み、Grafana がそのデータを読み取って表示します。
【Python監視スクリプト群】
nucbox_system_record.py(5秒ごと)
process_status_record.py(5秒ごと)
raspi_backup.py(毎日)
↓
【InfluxDB v2】measurement 単位でデータを蓄積
nucbox_system_log / process_status_log / backup_log …
↓
【Grafana】Flux クエリで各 measurement からデータを取得
→ サーバー監視ダッシュボードに表示
使用する Grafana パネルの種類
- Stat:最新の1値を大きく表示。CPU温度・使用率・稼働時間など現在値の確認に最適
- Gauge:0〜100%のゲージ表示。メモリ使用率・SSD消耗度など割合の視認性が高い
- Time series:時系列グラフ。CPU使用率の推移やプロセス別CPU使用の変化を確認
- Table:複数フィールドを表形式で表示。プロセス一覧・実行ログ一覧に使用
実装のポイント
閾値(Thresholds)で異常を色で警告する
Stat パネルや Gauge パネルでは Thresholds を設定することで、値に応じて自動的に色が変わります。正常・注意・危険の3段階で設定しておくと、ダッシュボードを開いた瞬間に異常箇所が目に入ります。
CPU温度の閾値設定例
Green(正常):〜70℃ / Yellow(注意):70〜85℃ / Red(危険):85℃〜
NUCBOX N100 の場合、通常負荷では 50〜60℃ 台で動作します。85℃を超えるとサーマルスロットリングが発生するため、その手前で警告色にします。
SSD消耗度の閾値設定例
Green(正常):〜50% / Yellow(注意):50〜80% / Red(危険):80%〜
percentage_used が 100% に近づくと設計寿命に達している目安になります。
ダッシュボードのリフレッシュ間隔
右上の Refresh 設定を 5s(5秒)にすることで、監視スクリプトの記録間隔に合わせてほぼリアルタイムにデータが更新されます。負荷が気になる場合は 30s や 1m に変更しても問題ありません。
last() と mean() の使い分け
Stat パネルで「現在値」を表示したい場合は last()、Time series で「推移」を見たい場合は aggregateWindow と mean() を組み合わせます。
事前準備
Grafana に InfluxDB v2 データソースを追加する
Grafana の管理画面から Connections → Data sources → Add data source で InfluxDB を選択し、以下の項目を設定します。
- Query Language:Flux
- URL:http://localhost:8086
- Organization:InfluxDB の Org 名
- Token:InfluxDB の API トークン
- Default Bucket:データを保存しているバケット名
新規ダッシュボードの作成
Grafana の Dashboards → New dashboard から新規ダッシュボードを作成します。
ダッシュボード名を「サーバー監視ダッシュボード」などとしておくと管理しやすいです。
実装方法
エリア① CPU・メモリ系パネル
CPU温度(Stat パネル)
from(bucket: "your-bucket")
|> range(start: -1m)
|> filter(fn: (r) => r._measurement == "nucbox_system_log")
|> filter(fn: (r) => r._field == "cpu_temp")
|> last()パネルタイプ:Stat / 単位:℃(Celsius) / Thresholds:70℃・85℃ で黄→赤
コア別 CPU 使用率(Stat パネル・複数値)
from(bucket: "your-bucket")
|> range(start: -1m)
|> filter(fn: (r) => r._measurement == "nucbox_system_log")
|> filter(fn: (r) => r._field =~ /^cpu_core[0-9]+_percent$/)
|> last()パネルタイプ:Stat / Value options → Fields:All fields でコアごとに値が並んで表示されます。
メモリ使用率(Gauge パネル)
from(bucket: "your-bucket")
|> range(start: -1m)
|> filter(fn: (r) => r._measurement == "nucbox_system_log")
|> filter(fn: (r) => r._field == "mem_percent")
|> last()パネルタイプ:Gauge / Min:0 / Max:100 / Thresholds:70% ・ 90% で黄→赤
エリア② SSD・ディスク系パネル
SSD 合成温度(Stat パネル)
from(bucket: "your-bucket")
|> range(start: -1m)
|> filter(fn: (r) => r._measurement == "nucbox_system_log")
|> filter(fn: (r) => r._field == "nvme_composite")
|> last()SSD 消耗度(Stat パネル)
from(bucket: "your-bucket")
|> range(start: -1m)
|> filter(fn: (r) => r._measurement == "nucbox_system_log")
|> filter(fn: (r) => r._field == "percentage_used")
|> last()パネルタイプ:Stat / 単位:% / Thresholds:50% ・ 80% で黄→赤
稼働時間(Stat パネル)
from(bucket: "your-bucket")
|> range(start: -1m)
|> filter(fn: (r) => r._measurement == "nucbox_system_log")
|> filter(fn: (r) => r._field == "power_on_hours")
|> last()単位を hours(h) に設定すると「11時間」のように表示されます。
エリア③ プロセス状況パネル
プロセス別リソース使用状況(Table パネル)
親プロセス(is_parent = true)のみを絞り込んで、プログラム名・サービス状態・CPU・メモリを表形式で表示します。
from(bucket: "your-bucket")
|> range(start: -1m)
|> filter(fn: (r) => r._measurement == "process_status_log")
|> filter(fn: (r) => r._field == "cpu_percent" or r._field == "memory_percent")
|> filter(fn: (r) => r.is_parent == "true")
|> last()
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")パネルタイプ:Table
表示する列:program_name(タグ)・service_name(タグ)・cpu_percent・memory_percent
Column styles で cpu_percent に Thresholds(80%・90%)を設定すると、高負荷プロセスをハイライトできます。
自作アプリの実行ログ(Table パネル)
execution_log measurement を使って、自作アプリの最近の実行状況を一覧表示します。
from(bucket: "your-bucket")
|> range(start: -24h)
|> filter(fn: (r) => r._measurement == "execution_log")
|> filter(fn: (r) => r._field == "message")
|> sort(columns: ["_time"], desc: true)
|> limit(n: 20)エリア④ バックアップ・統計パネル
最終バックアップ時刻(Stat パネル)
バックアップの最終実行から何時間経過したかを表示します。
from(bucket: "your-bucket")
|> range(start: -30d)
|> filter(fn: (r) => r._measurement == "backup_log")
|> filter(fn: (r) => r._field == "backup_size")
|> last()
|> map(fn: (r) => ({r with _value: int(v: uint(v: now()) - uint(v: r._time)) / 1000000000 / 3600}))単位を hours に設定し、Thresholds で 25h(24時間以上経過は警告)・48h(赤)に設定します。
バックアップ先の空き容量(Stat パネル)
from(bucket: "your-bucket")
|> range(start: -30d)
|> filter(fn: (r) => r._measurement == "backup_log")
|> filter(fn: (r) => r._field == "free_size")
|> last()
|> map(fn: (r) => ({r with _value: float(v: r._value) / 1073741824.0}))単位を GB に設定し、Thresholds で空き容量が少なくなったら警告色にします。
コードの解説
正規表現フィルターで複数フィールドをまとめて取得
|> filter(fn: (r) => r._field =~ /^cpu_core[0-9]+_percent$/)=~ 演算子で正規表現フィルターを使うと、cpu_core0_percent・cpu_core1_percent・cpu_core2_percent・cpu_core3_percent を1つのクエリでまとめて取得できます。コア数が変わっても修正不要です。
pivot で複数フィールドを1行にまとめる
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")InfluxDB のデータは1フィールド=1行で返ってきます。Table パネルで複数フィールドを横並び(1プロセス=1行)にしたい場合は pivot() で変換します。columnKey にフィールド名、valueColumn に値を指定することで、フィールド名が列名になります。
時間差を計算して「〇時間前」を表示する
|> map(fn: (r) => ({r with _value: int(v: uint(v: now()) - uint(v: r._time)) / 1000000000 / 3600}))now() から最終レコードのタイムスタンプを引いて経過秒数を求め、3600で割って時間単位にします。
InfluxDB の時刻型は uint 型にキャストしてから演算する必要があります。
aggregateWindow でグラフを間引いて表示
from(bucket: "your-bucket")
|> range(start: -24h)
|> filter(fn: (r) => r._measurement == "nucbox_system_log")
|> filter(fn: (r) => r._field == "cpu_percent")
|> aggregateWindow(every: 1m, fn: mean, createEmpty: false)5秒ごとのデータをそのまま24時間分表示すると点が多すぎてグラフが重くなります。aggregateWindow(every: 1m, fn: mean) で1分ごとの平均値に集約することで、視認性と表示速度を両立させます。
動作確認
パネルの動作確認手順
- パネル編集画面のクエリエディタで Flux クエリを貼り付けて Run query を押す
- プレビューにデータが表示されることを確認する
- 右上の時間範囲を Last 1 hour に変えてもデータが表示されるか確認する
- ダッシュボードを保存して Auto refresh を 5s に設定し、リアルタイム更新されることを確認する
パネルに「No data」と表示される場合は、まず InfluxDB Data Explorer で直接同じ Flux クエリを実行してデータが存在するか確認してください。データはあるが Grafana に表示されない場合は、データソースの設定(Token・Bucket名・Org名)を再確認してください。
まとめ
本記事では、Python 監視スクリプトが InfluxDB v2 に蓄積したサーバー情報を Grafana で一元可視化するダッシュボードの作り方を解説しました。
- Stat・Gauge・Table・Time series の各パネルを使い分けることで、現在値・割合・一覧・推移をそれぞれ最適な形で表示できる
- Thresholds(閾値) を設定することで、ダッシュボードを見た瞬間に異常箇所が色で目に入るようになる
- Flux の 正規表現フィルター・pivot・aggregateWindow を組み合わせると、複数フィールドの効率的な取得・整形・間引きが実現できる
- 各監視スクリプトの記事で紹介したデータがすべて InfluxDB に蓄積されているため、あとは Grafana でパネルを追加するだけで表示できる
ダッシュボードが完成したら NGINX のリバースプロキシ経由で外部から HTTPS アクセスできるようにしておくと、外出先からもサーバーの状態を確認できるようになります。